The gist for this lambda function can be found here.
A common task in Natural Language Processing (NLP) is to tokenize text strings into n-grams. This can be done easily in languages like Python, Scala, R and others. They have very good libraries for performing that kind of task at scale.
I wanted to see whether something like that would be possible with an Excel LAMBDA function.
=LAMBDA(
text,
n,
strict,
LET(
words,TEXTSPLITXML(text," "),
wordcount,ROWS(words),
witherrors,
MAKEARRAY(
wordcount,
n+1,
LAMBDA(
r,
c,
IF(
c=1,
text,
INDEX(
LET(
ind,MAKEARRAY(wordcount,n,LAMBDA(r,c,r+c-1)),
INDEX(words,ind)
),
r,
c-1
)
)
)
),
IF(
strict,
FILTER(
witherrors,
BYROW(
witherrors,
LAMBDA(a,SUM(N(ISERROR(a)))))=0
)
,witherrors
)
)
)
I call this NGRAMS and at the moment, it splits text into arrays of words of n words each. It takes three arguments:
- text – the text you want to calculate n-grams for
- n – the number of words that should be in each array
- strict – whether or not you only want arrays containing exactly n items (what this means will become clear below)
A key helper-LAMBDA for this is TEXTSPLITXML. This function can be used to split a text string into an array of words.
=LAMBDA(
text,
delim,
FILTERXML(
"<x><y>"&SUBSTITUTE(text,delim,"</y><y>")&"</y></x>",
"//y"
)
)
I freely and gladly admit that I found and used that function directly from this page at the incredible Excel resource EXCELJET. If I don’t know how to do something in Excel, that’s where I go. This is what TEXTSPLITXML does:
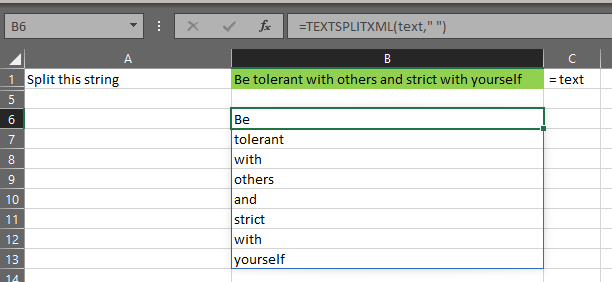
You can see in the NGRAMS function at the top of this page that I’m assigning the result of TEXTSPLITXML to the name “words”. I’m then assigning the number of rows in “words” to the name “wordcount”.
I’m then creating an array called “witherrors”. This uses MAKEARRAY to build the output of NGRAMS.
MAKEARRAY has three arguments:
- The number of rows – in this case, I am using “wordcount” – which is the maximum number of ngrams I can create from a string, where n = 1
- The number of columns – in this case, I’m using n+1, because each ngram will be on a row of its own and each element of each ngram will take one column on that row. I’m adding one because I want to display the original string next to each ngram in the finished array
- A LAMBDA function to populate the array
The LAMBDA function to populate the array is:
LAMBDA(
r,
c,
IF(
c=1,
text,
INDEX(
LET(
ind,MAKEARRAY(wordcount,n,LAMBDA(r,c,r+c-1)),
INDEX(words,ind)
),
r,
c-1
)
)
)
When we use a LAMBDA in the third argument of MAKEARRAY, the first two arguments of that LAMBDA are always interpreted to be the row of the new array and the column of the new array.
So, we’re saying, if the column is 1, then place the original string (“text”) in the new array.
Otherwise, return a value from row=r, column=c-1 of the array defined inside the LET statement.
LET(
ind,MAKEARRAY(wordcount,n,LAMBDA(r,c,r+c-1)),
INDEX(words,ind)
)
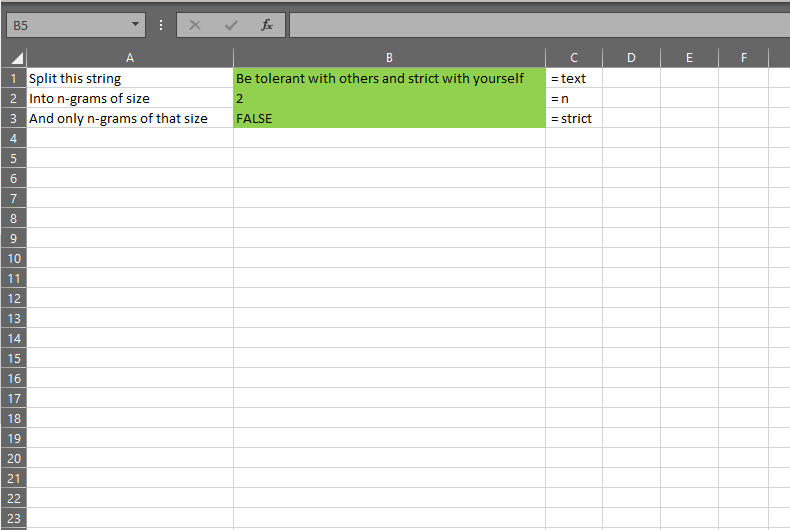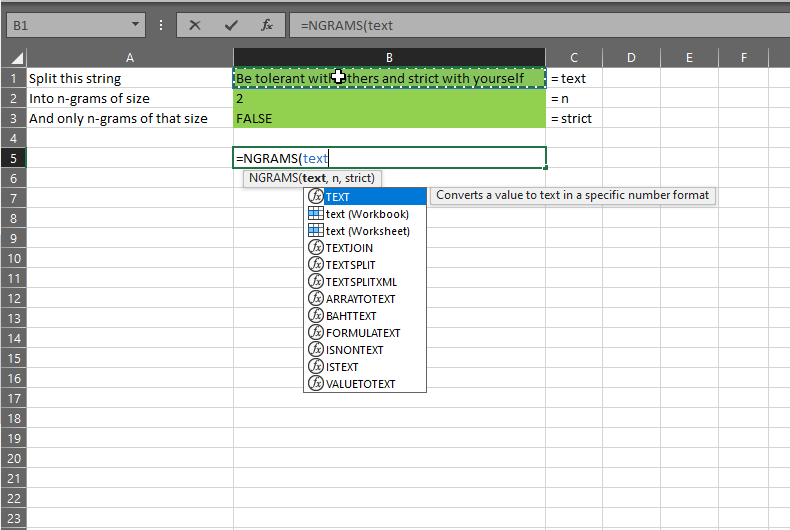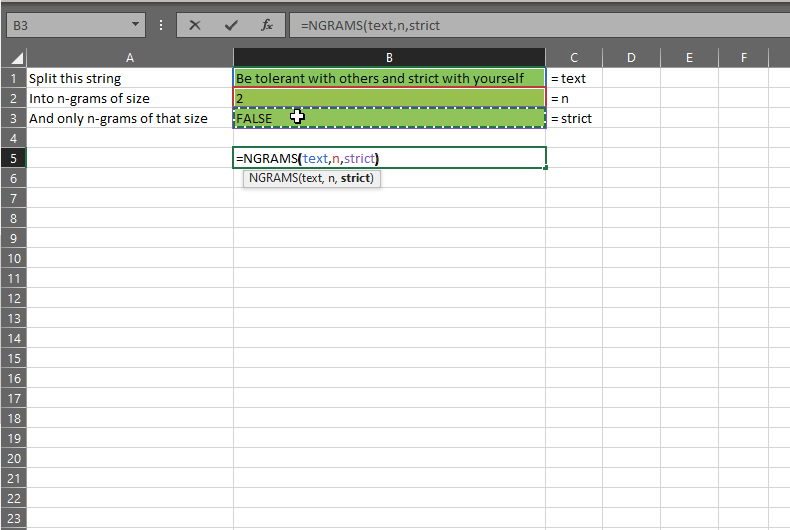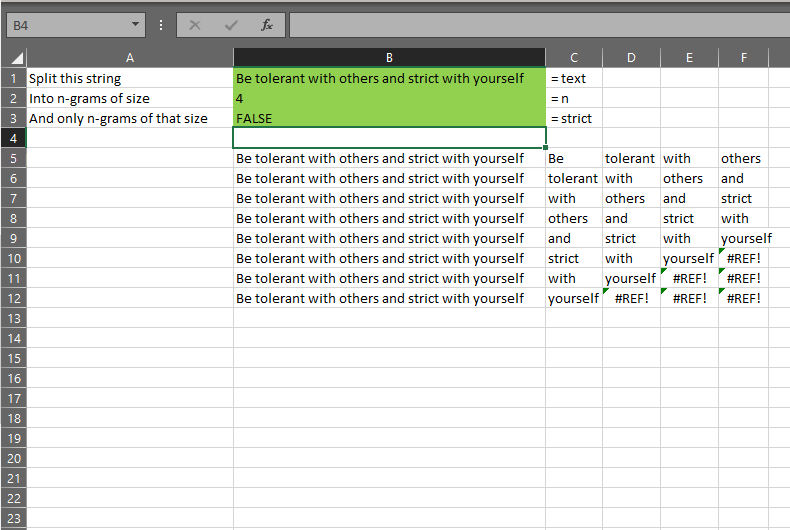
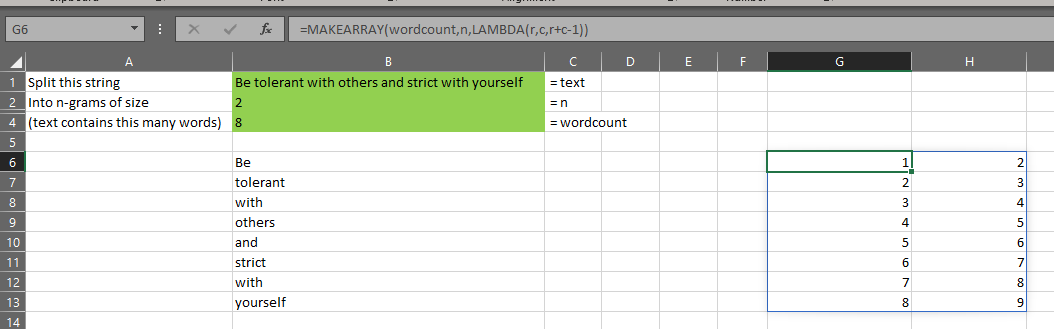
For the sentence “Be tolerant with others and strict with yourself”, we have 8 words. Suppose we want to calculate the bigrams from this text.
This should represent each two-word pair:
- Be tolerant
- tolerant with
- with others
- …etc
- with yourself
If the array returned by TEXTSPLITXML has 8 words, then the index of those words is {1,2,3,4,5,6,7,8}. So, to build each bigram, we can refer to the indexes and create an index array
- {1,2}
- {2,3}
- {3,4}
- …etc
- {7,8}
Or more correctly:
{1,2;2,3;3,4;4,5;5,6;6,7;7,8}
Considering the row and column indexes r and c, each cell of such an array is populated with r+c-1, as you can see in cell G6 below:
So, that inner-most MAKEARRAY has created that grid of numbers you can see above. This array is given the name “ind”. The calculation part of the surrounding LET is then using INDEX(words,ind) to retrieve the words at each position represented by the index array shown above.
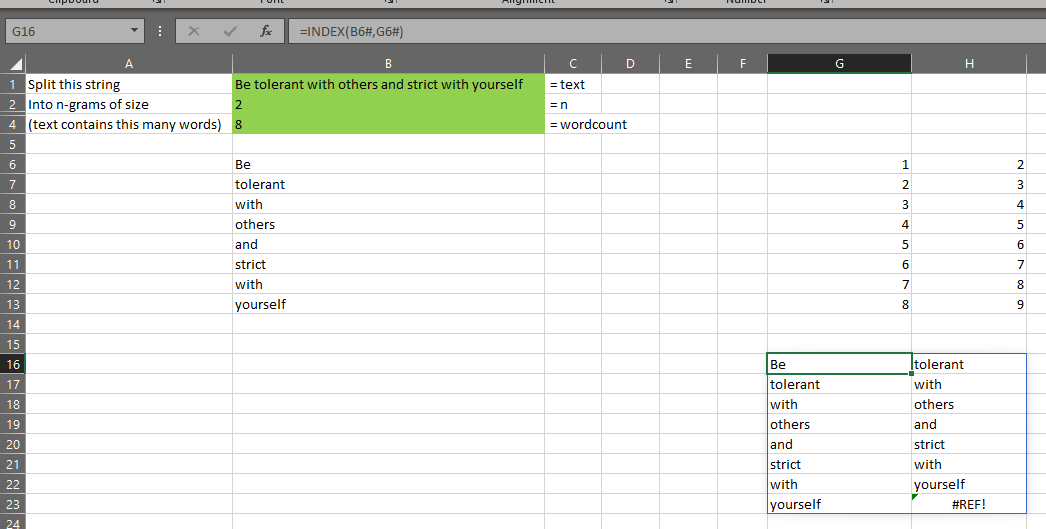
As you can see, this INDEX(words,ind) shown in cell G16 above returns the bigrams of the text in cell B2, as well as an extra row which has the last word and an error.
This array of words is given the name “witherrors”.
The final calculation of the NGRAMS LAMBDA is an IF block to remove any rows that have errors if the caller has passed strict=TRUE. This is done by calculating the number of non-error cells in each row and comparing it with n.
If they are the same, the row doesn’t have any cells with error values. If they’re not the same, it has at least one cell with an error value.
So, the array returned by BYROW is an array of TRUE for rows with errors and FALSE for rows without errors. This array is used to FILTER the “witherrors” array and return the resulting array to the outer MAKEARRAY call and place it next to the column containing the original text on each row.
I know, I know. That feels like a lot. And I’m not 100% clear on the application of this kind of thing in Excel, but it’s been an interesting learning exercise nonetheless!
Sometimes that’s enough.
Please leave a comment if you have any questions or if you think there’s a simpler way to do this.