Last week I wrote about some of the newer innovations in the SQL space. This got me thinking. What other language features would be useful in a SQL environment?
This post explores some ideas I’ve had around this. It’s purely speculative, but perhaps it will spark some ideas for you.
1. Optional GROUP BY clause
In most GROUP BY queries, every non-aggregate must be listed in the GROUP BY clause. Sure, we have options, like GROUP BY 1, 2, 3 or GROUP BY ALL, but while these are convenient, they’re also busywork for most queries.
So my first suggestion is that if we create a SELECT clause that includes an aggregate, then if we omit the GROUP BY clause, then GROUP BY ALL is inferred.
For example:
SELECT
category,
region,
SUM(sales) AS total_sales
FROM
orders;
GROUP BY is omitted, so GROUP BY ALL is inferred from the SUM in the SELECT clause.
2. Simplified aggregates
Take a look at this query:
SELECT
region,
SUM(revenue) AS total_revenue,
SUM(expenses) AS total_expenses,
SUM(revenue - expenses) AS total_profit,
AVG(order_size) AS avg_order_size,
AVG(quantity) AS avg_quantity
FROM
orders
-- (group by omitted per list item 1!)
Pretty simple. Three SUMs, then two AVGs. Seems a bit wordy though, no? What about this instead?
SELECT
region,
AGGREGATE
SUM (revenue, expenses, revenue - expenses),
AVG (order_size, quantity)
FROM
orders;
I get it, this isn’t going to be appropriate for every aggregate query. But what language feature is? The point here is one of convenience. Want to add a nother SUM to your query? Whack it inside the existing SUM call.
But what about aliases? Well, I think we keep it simple. If you omit an alias, you get what you normally get when you do that. Here’s what happens in SQL Server Management Studio:
USE testing;
DROP TABLE IF EXISTS Sales;
CREATE TABLE sales (
region NVARCHAR(4),
revenue FLOAT,
expenses FLOAT
);
GO
INSERT INTO sales (region, revenue, expenses) VALUES
('East', 1000, 800),
('East', 1200, 950),
('West', 1500, 1000),
('West', 1700, 1200);
SELECT
region,
SUM(revenue),
SUM(expenses),
SUM(revenue - expenses)
FROM sales
GROUP BY region;
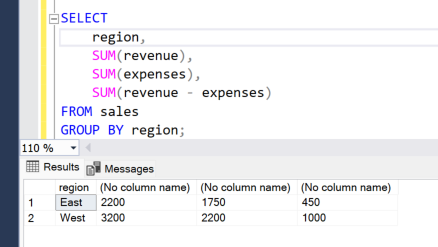
As you can see, you get ‘(No column name)’ if you don’t give an alias. This varies by IDE, so let’s leave that as-is.
If we want to alias a column, we’ll just use existing syntax:
SELECT
region,
AGGREGATE
SUM (revenue AS total_revenue, expenses AS total_expenses, (revenue - expenses) AS total_profit),
AVG (order_size AS avg_order_size, quantity AS avg_quantity)
FROM
orders;
Getting longer, I see. But we can always add line-breaks between each column in an aggregate function. And of course, we needn’t alias at all if we’re working alone in the dark but familiar corners of the gloaming.
3. REORDER clause
I really like this one. If SELECT can have RENAME, REPLACE and EXCLUDE, then it should also have REORDER.
The simple idea is that as we’re building a query, we might end up with columns in an order that we later decide is not what we want. So we add a simple REORDER clause at the end and boom! we can change the order of how the columns are output!
As a simple example, this query would output in this order: another_column, that_column, this_column
SELECT
this_column,
that_column,
another_column
FROM
table
REORDER
3, 2, 1;
And of course we’d be able to use it with SELECT * and any of the interesting innovations available in Snowflake and BigQuery mentioned above to really make things interesting!
I’m not saying this is something you would push into a production pipeline. Rather, when you’re deep in the weeds of your exploratory analysis or writing that quick Friday-at-5pm report for your boss, you can change the order of the columns as you iterate before settling on that final cut/paste of the SELECT clause.
4. Natural language SQL
Lots of vendors at the moment are pursuing the laudable goal of text-to-SQL. In that model, you ask a question and an LLM writes a full SQL query for you.
But this is not without its problems, primarily how does the model accurately translate what you’re asking into what you want. With the advent of MCP tools, we can now pretty confidently represent a database to a model, so things will no doubt improve. But the problem remains of whether the language in the prompt is good enough to form a coherent query that is fit to purpose.
So what I’m suggesting here is a blend of that idea with the structured nature of the language that already exists.
An example:
SELECT top 10 biggest customers BY revenue
FROM orders;
Looks ridiculous, right? And of course, this is such a simple example that “Give me the top 10 biggest customers by revenue” as a prompt would no doubt get the correct result.
But what about this?
SELECT top 10 biggest customers BY revenue
FROM orders
WHERE order_date > three years ago;
Getting a little more interesting. The model could automatically write the expression for the right-hand operand of that WHERE inequality.
Still, probably doable by an LLM. What about this though?
SELECT top 5 customers BY average_monthly_spend
WHERE order_date > three years ago
AND monthly_spend increased IN at least 6 months
HAVING total_spend > 10000
This is perhaps the least fleshed-out idea on this post, but I think it has potential to bridge the gap between the much-appreciate structure of SQL and the raw expressive power of an LLM.
5. Aggregation presets
Recall the query from earlier in this post (this time without any of the ideas implemented):
SELECT
region,
SUM(revenue) AS total_revenue,
SUM(expenses) AS total_expenses,
SUM(revenue - expenses) AS total_profit,
AVG(order_size) AS avg_order_size
FROM sales
GROUP BY region;
An aggregation preset is something defined in a script (or presumably at the schema or database level) which can pre-define commonly used aggregates. Like this:
CREATE AGGREGATE finance_metrics AS
SUM(revenue) AS total_revenue,
SUM(expenses) AS total_expenses,
SUM(revenue - expenses) AS total_profit;
CREATE AGGREGATE sales_metrics AS
AVG(order_size) AS avg_order_size,
COUNT(order_id) AS order_count;
Or using idea 2 from above:
CREATE AGGREGATE finance_metrics AS
SUM(revenue AS total_revenue, expenses AS total_expenses, revenue - expenses AS total_profit);
CREATE AGGREGATE sales_metrics AS
AVG(order_size) AS avg_order_size,
COUNT(order_id) AS order_count;
Then we could use these defined aggregates anywhere (as well as omitting that pesky GROUP BY clause!):
SELECT
region,
AGGREGATE finance_metrics,
AGGREGATE sales_metrics
FROM sales;
Conclusion
So there you have it! 5 ideas for some new SQL language features. Maybe you like them, maybe you don’t! My favorite is probably number 1, though I admit it’s probably quite controversial among traditional SQL programmers! I think the natural language SQL has a good chance of becoming a reality in the near future.
What do you think?
Leave a Reply