The gist for the lambdas shown in this post can be found here.
When importing this gist, be sure to select “Add formulas to new namespace” and use the name “depn”.
The goal
There are several methods of calculating depreciation in Excel.
The functions SLN (straight line) , DB (declining balance) , DDB (double declining balance) and SYD (sum-of-years’ digits) are commonly used.
In addition, it’s useful to calculate a table showing the depreciation in each period over the life of the asset. As an example, this table shows the depreciation of an asset with a life of 9 years using the SLN function:
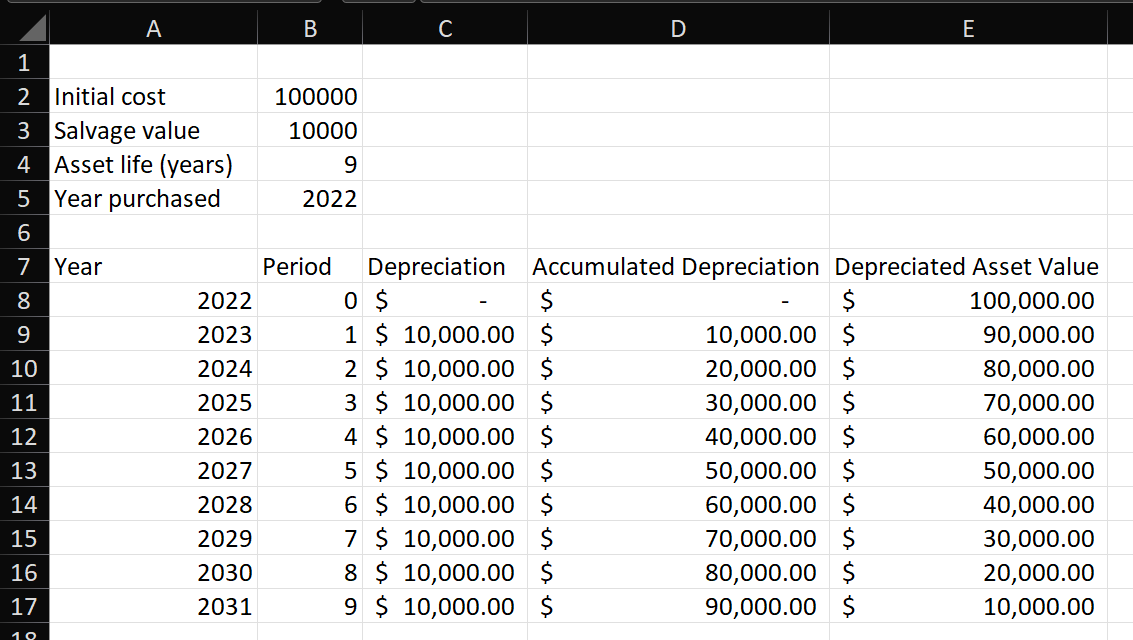
We can easily transpose this table to have the time periods on the column axis.
The SLN function is only used in the “Depreciation” column. Everything else is independent of the function used to calculate that column.
Further to this, the functions that can be used to calculate depreciation generally share the same parameters:
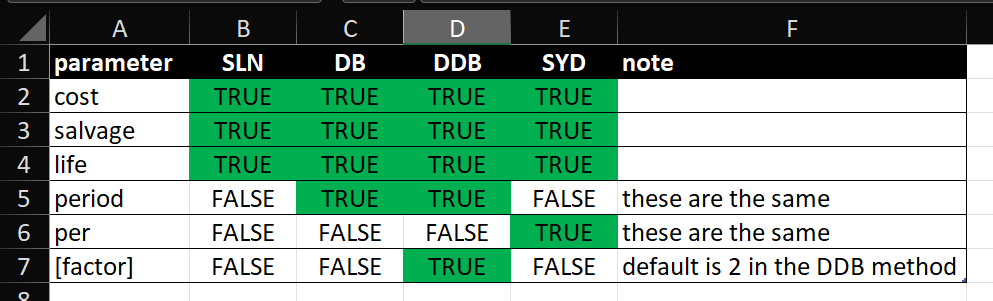
So, if we ignore the [factor] parameter only used by DDB, we can consider a generic function fn(cost, salvage, life, period) to calculate depreciation where fn is one of {SLN,DB,DDB,SYD}.
With all of that in mind, the goal of this post will be to:
Create a lambda to produce an asset depreciation schedule with a parameterized depreciation function
A solution
Here’s a lambda called depn.schedule:
schedule = LAMBDA(cost,salvage,life,purchase_year,function,[return_header],[vertical],
LET(
/*handle missing return_header argument*/
_rh,IF(ISOMITTED(return_header),TRUE,return_header),
/*handle missing vertical argument*/
_v,IF(ISOMITTED(vertical),FALSE,vertical),
/*create an array that is life+1 rows, starting at 0*/
_periods,SEQUENCE(life+1,,0),
_years,purchase_year + _periods,
/*apply the depreciation function to the inputs*/
_depr,IFERROR(function(cost,salvage,life,_periods),0),
/*calculate the accumulated depreciation over the life of the asset*/
_acc,SCAN(0,_depr,LAMBDA(a,b,a+b)),
_depr_val,cost-_acc,
_header,{"Year","Period","Depreciation","Accumulated Depreciation","Depreciated Asset Value"},
/*place the various vectors in an array - one row per year, one column per vector
(simpler with HSTACK)*/
_arr,CHOOSE({1,2,3,4,5},_years,_periods,_depr,_acc,_depr_val),
/*append the header to the array
(simpler with VSTACK)*/
_arr_with_header,MAKEARRAY(life+2,5,LAMBDA(r,c,IF(r=1,INDEX(_header,1,c),INDEX(_arr,r-1,c)))),
/*if the calling function has passed [return_header]=FALSE, then return _arr,
otherwise return _arr_with_header*/
_output,IF(_rh,_arr_with_header,_arr),
/*if the calling function has passed [vertical]=TRUE, then
return with years on rows, otherwise return with years on columns*/
IF(_v,_output,TRANSPOSE(_output))
)
);
depn.schedule takes five required parameters:
- cost – the cost of the asset.
- salvage – the salvage value of the asset at the end of its life.
- life – the life (in years) of the asset. This should be an integer.
- purchase_year – the year the asset was purchased, which should be a four-digit integer.
- function – the function to use to calculate the depreciation. This must be one of:
- depn.sln (for straight-line)
- depn.db (for declining balance)
- depn.ddb (for double-declining balance)
- depn.syd (for sum-of-years’ digits)
- [return_header] – OPTIONAL – indicates whether to return the header. Default is TRUE.
- [vertical] – OPTIONAL – indicates whether to return the years on rows (TRUE) or columns (FALSE). Default is FALSE.
The fifth parameter to the lambda above is a function that calculates depreciation.
While we can certainly add more, and really it need only be any function that takes 4 parameters, the intent is to use one of the following four names.
Each of these is in the same namespace as the schedule function above, and as such are referred to by depn.sln, depn.db, depn.ddb and depn.syd:
sln = LAMBDA(cost,salvage,life,periods,
LET(
v,SLN(cost,salvage,life),
MAKEARRAY(ROWS(periods),1,LAMBDA(r,c,IF(r=1,0,v)))
)
);
db = LAMBDA(cost,salvage,life,periods,
DB(cost,salvage,life,periods)
);
ddb = LAMBDA(cost,salvage,life,periods,
DDB(cost,salvage,life,periods)
);
syd = LAMBDA(cost,salvage,life,periods,
SYD(cost,salvage,life,periods)
);
There’s nothing special about these functions – in each case they are simply creating a vector of depreciation values for the periods passed into the fourth parameter.
The only one that’s slightly different is depn.sln. It calls Excel’s native SLN function, which doesn’t take a period parameter (since all periods have the same depreciation – it’s a straight line). As such, we build the vector manually to ensure a zero in the first row and a fixed depreciation amount in every other row.
By defining these as lambda functions, we can now pass them as a parameter to the depn.schedule function.
This is how it works:
As mentioned above, we can easily pivot this output such that the years are on the column axis by either omitting the vertical parameter or setting it to FALSE.
As you can see, using this function makes it trivially simple to create a table illustrating the depreciation of a fixed asset. You can grab the code from the gist linked at the top of this post if you want to use it. If you’d like to understand how it works, please read on.How it works
As a reminder, the steps of the depn.schedule function are:
schedule = LAMBDA(cost,salvage,life,purchase_year,function,[return_header],[vertical],
LET(
/*handle missing return_header argument*/
_rh,IF(ISOMITTED(return_header),TRUE,return_header),
/*handle missing vertical argument*/
_v,IF(ISOMITTED(vertical),FALSE,vertical),
/*create an array that is life+1 rows, starting at 0*/
_periods,SEQUENCE(life+1,,0),
_years,purchase_year + _periods,
/*apply the depreciation function to the inputs*/
_depr,IFERROR(function(cost,salvage,life,_periods),0),
/*calculate the accumulated depreciation over the life of the asset*/
_acc,SCAN(0,_depr,LAMBDA(a,b,a+b)),
_depr_val,cost-_acc,
_header,{"Year","Period","Depreciation","Accumulated Depreciation","Depreciated Asset Value"},
/*place the various vectors in an array - one row per year, one column per vector
(simpler with HSTACK)*/
_arr,CHOOSE({1,2,3,4,5},_years,_periods,_depr,_acc,_depr_val),
/*append the header to the array
(simpler with VSTACK)*/
_arr_with_header,MAKEARRAY(life+2,5,LAMBDA(r,c,IF(r=1,INDEX(_header,1,c),INDEX(_arr,r-1,c)))),
/*if the calling function has passed [return_header]=FALSE, then return _arr,
otherwise return _arr_with_header*/
_output,IF(_rh,_arr_with_header,_arr),
/*if the calling function has passed [vertical]=TRUE, then
return with years on rows, otherwise return with years on columns*/
IF(_v,_output,TRANSPOSE(_output))
)
);
As usual, we use LET to define variables:
- _rh – here we handle the optional [return_header] parameter. If it is not provided, we set a default of TRUE, otherwise we use the value provided. If the argument passed is text, the function will error. Otherwise a zero will equate to FALSE and any other non-zero number will equate to TRUE.
- _v – similarly, we handle the optional [vertical] parameter. If the parameter is omitted, the default is FALSE (horizontal layout), otherwise use the argument passed.
- _periods – we create a sequence of integers that’s life+1 rows long, starting at 0 (the purchase year). For example, for life=5, _periods = {0,1,2,3,4,5}
- _years – we simply add the purchase year to the _periods array, which gives us a list of years. For example, for purchase_year = 2022 and life = 5, _years = {2022,2023,2024,2025,2026,2027}
- _depr – here we use the function passed into the function parameter to calculate the depreciation in each period. As mentioned before, exactly what this function does is dependent on the method used (depn.sln, depn.db, depn.ddb or depn.syd). All that is required here is a function that will accept the arguments being passed in this definition. So, if you wanted to add another method, you would only need to define a new lambda for that method, then pass the name of that lambda as the fourth argument to depn.schedule.
- _acc – here we SCAN through the _depr vector and calculate a running sum by adding each row to the result of the scan on the previous row (a+b).
- _depr_val – is just the cost minus the accumulated depreciation.
- _header – is a one-row array of headers. Edit as you prefer.
- _arr – here we put each of the five columns next to each other using CHOOSE. This is also easily possible with HSTACK if you are an Office Insider.
- _arr_with_header – we use MAKEARRAY to stack the _header variable on top of the _arr variable. Again, this is possible and easier with VSTACK. I have not used VSTACK here because it is not currently widely available.
- _output – here we are checking the _rh variable (return header) to determine whether to return either _arr or _arr_with_header.
- And finally, we check the _v variable to decide whether to return the table as a horizontal schedule or a vertical schedule.
In summary
That’s how to create a depreciation schedule in Excel with one function.
Excel provides several native functions for different methods of calculating depreciation of a fixed asset.
By first comparing the parameters between the different methods and standardizing their inputs by wrapping them in the LAMBDA function, we can pass them as a parameter to a function that produces a depreciation schedule.
I hope this is useful and sparks some ideas for using lambda to simplify your work.
Please leave a comment below if you have any ideas for other lambdas for FP&A.
Luigi says:
Buenas tardes, estuve estudiando su código para cálcular la depreciación en cascada, y estaba tratando de adaptar el código, a la siguiente forma de obtener los datos:
Tiempo 31/12/2023 31/01/2024 29/02/2024 31/03/2024 30/04/2024
Maquinaria 10,000.00 0.00 0.00 0.00 6,000.00
Equipo 0.00 5,000.00 0.00 10,000.00 0.00
Life Maq 5.00 0 0 0 2
Life Equipo 0 5 0 4 0
Al adaptar el código, tengo un problema al sumarizar, dado que puedo tener más de un asset (con el mismo nombre) en un periodo de tiempo que cruza con otro por ejemplo: Maquinaria de 10M con vida util de 5 meses y Maquinaria de 6M con vida util de 2 años.
Este es el código que adapté: =depre_n.waterfall(B13:H14;B16:H17;B12:H12;A13:A14;F1;F2)
schedule = LAMBDA(cost,periods,start,
LET(
_periods,SEQUENCE( periods+1 ,1,0),
_depr,IFERROR(IF(_periods=0,0,SLN(cost,0,periods)),0),
_acc,SCAN(0,_depr,LAMBDA(a,b,a+b)),
_periodslabels,
EOMONTH(start,_periods)
,
_dav,cost-_acc,
_array,CHOOSE({1,2,3,4,5},_periodslabels,_periods,_depr,_acc,_dav),
_output,IF(_array,_array),
_output
)
);
array_create = LAMBDA(Rows,Columns,Defaults,
LET(D,IF(COLUMNS(Defaults)>1,
INDEX(Defaults,1,0),
LEFT(INDEX(Defaults,1,1),
SEQUENCE(1,Columns,
LEN(INDEX(Defaults,1,1)),0))),
X,SEQUENCE(1,Columns),
Y,SEQUENCE(Rows,1,1,0),
IFERROR(INDEX(D,1,X*Y),””)));
schedule_stack = LAMBDA(t,tv,tt, tc,
LET(
f_asset, ROWS(t) ,
f_vida, ROWS(tv) ,
f_time, ROWS(tt) ,
f_concepto, ROWS(tc),
c_asset, COLUMNS(t) ,
c_vida, COLUMNS(tv) ,
c_time, COLUMNS(tt) ,
indice_f_asset, SEQUENCE(f_asset,1,1),
indice_f_vida, SEQUENCE(f_vida,1,1),
indice_c_asset, SEQUENCE(1,c_asset,1),
indice_c_vida, SEQUENCE(1,c_vida,1),
tc_c, array_create(f_asset,f_concepto,transpose(tc)),
info_table, LAMBDA(b,
//VSTACK(
HSTACK(INDEX(tc_c,,b) , INDEX(t, indice_f_asset, b), INDEX(tv, indice_f_vida,b ), INDEX(tt, , 1))
//HSTACK(INDEX(t, , b), INDEX(tv, , b), INDEX(tt, , 1))
//)
),
//info_table(0),
//GetVal, LAMBDA(row, LAMBDA( col , INDEX( info_table({1,2}) , row , col) ) ),
resultado, VSTACK(
info_table(1),info_table(2)
),
GetVal, LAMBDA(row, LAMBDA( col , INDEX( resultado , row , col) ) ),
Schedule, LAMBDA(b,
LET(
//get a lambda containing the row for this asset
args,GetVal(b),
//create the schedule
depre_n.schedule(
args(2) , //cost
args(3) , //life
args(4) //start
)
)
),
Schedule1, Schedule(1) ,
//Creates a 1-column array containing the asset name
AssetNameCol, LAMBDA( name , sch , EXPAND( name , ROWS(sch) , 1 , name )),
RowIndex, SEQUENCE( ROWS( Schedule(0) ) ),
//prepare the column for the first asset
NameCol1 , AssetNameCol( GetVal(1)(1) , Schedule1 ),
//create the initial value for the REDUCE operation
Init , HSTACK( NameCol1 , Schedule1 ),
Schedules,
REDUCE(
Init , //initial array – the schedule for row 1
DROP( RowIndex , 1 ), //scan the rest of the rows
LAMBDA( a , b ,
LET(
//get the schedule for the current row/asset
Schedule_b, Schedule(b),
//make a column containing the asset name with same number of rows as schedule
NameCol_b, AssetNameCol( GetVal(b)(1) , Schedule_b ) ,
VSTACK(
a, //the previous schedules
HSTACK( NameCol_b , Schedule_b ) //the current schedule
)
)
)
),
Schedules
)
);
waterfall = LAMBDA(
asset_purchases_table,
vida_table,
time_table,
concepto_table,
//depn_fn,
start,
end,
//[period_fn],
[vertical],
LET(
omitted,ISOMITTED(asset_purchases_table)+ISOMITTED(start)+ISOMITTED(end),
IF(omitted,”ERROR: asset_purchases_table, depn_fn, start or end is missing”,
LET(
t, transpose(asset_purchases_table) ,
tv,transpose(vida_table) ,
tt,transpose(time_table) ,
tc,concepto_table ,
ReturnVertical, IF( ISOMITTED( vertical ), FALSE , vertical ) ,
//total count of periods to include is the difference between start and end
//according to the period function given
PeriodCount, ROWS(asset_purchases_table),
PeriodLabels, tt,
/*Returns a vertical table of stacked schedules for each asset
listed in the control table, with the asset name in the first
column.
*/
ScheduleStack, depre_n.schedule_stack( t, tv, tt, tc ),
Assets, tc ,
GetAssetDepn,
LAMBDA(x,
LET(
FilteredDepn, FILTER( DROP( ScheduleStack , 0 , 1 ) , CHOOSECOLS( ScheduleStack , 1 ) = x ) ,
XLOOKUP( PeriodLabels , CHOOSECOLS( FilteredDepn , 1 ) , CHOOSECOLS( FilteredDepn , 3 ) , 0 )
//SUMIFS(CHOOSECOLS( FilteredDepn , 3 ),CHOOSECOLS( FilteredDepn , 1 ),PeriodLabels)
)
) ,
Schedules,
REDUCE(
GetAssetDepn( TAKE( Assets , 1 ) ),
DROP( Assets , 1 ),
LAMBDA(a,b,
HSTACK( a , GetAssetDepn(b) )
)
),
Totals, BYROW( Schedules , LAMBDA(r, SUM( r ) ) ),
Result,
VSTACK(
HSTACK( “” , TRANSPOSE( Assets ) , “Total” ),
HSTACK( PeriodLabels , Schedules , Totals )
),
IF( ReturnVertical , Result , TRANSPOSE( Result ) )
)
);
Por favor podrá ayudarme a adaptar a los inputs?.
OP says:
Hi Luigi
Thanks for your comment. I’ll need a little while to digest this and hopefully come back with something useful. I have been planning on re-writing these functions for a while, so I might do that first and then see if we can account for duplicated names in the new version.
Cheers