The gist for this lambda function can be found here.
Preface
This post is a follow up to an earlier post. I wrote the function described there in May of 2022, before I had access to functions like VSTACK and HSTACK and before I had a solid understanding of SCAN and REDUCE. As such, while it was fun to write and worked just fine, it was a monster of a function!
The recent release of the GROUPBY and PIVOTBY functions (described here) also came with a huge upgrade to the LAMBDA experience. To cut a long-story short, with this release, we are now able to pass native functions as arguments to other functions.
As a very simple example, where before we might have had to do this to calculate column totals for an array:
=BYCOL(my_array, LAMBDA(c, SUM(c)))
The upgrade means we can now do this instead:
=BYCOL(my_array, SUM)
In short, instead of having to wrap the SUM function in a LAMBDA for it to be accepted as an argument to BYCOL, we can now simply pass the SUM function itself and BYCOL will interpret it as “single argument function” and pass the only argument BYCOL creates – a column from the array – into SUM.
The goal
If we have a table of sales of a product where each row represents one month, then we might want to calculate – for each month – the rolling sum of sales over the most recent three months.
When we sum a variable over multiple rows like this, the rows we are summing over are referred to as a “window” on the data. So, functions that apply calculations over a rolling number of rows are referred to as “window functions”.
These window functions are available in almost all flavors of SQL.
They’re also available in the Python Pandas package. In Pandas, we can use window functions by making calls to rolling.
The goal here is to mimic the functionality seen in pd.rolling by providing a generic and dynamic interface for calculating rolling aggregates.
rolling.aggregate – a simplified solution
This is the lambda function rolling.aggregate. The intention is that you would use the function below in an Advanced Formula Environment module called ‘rolling’:
aggregate =LAMBDA(x,window,
LAMBDA(function,
LET(
_i,SEQUENCE(ROWS(x)),
MAP(_i,
LAMBDA(b,
IF(
b < window,
NA(),
function(INDEX(x, b - window + 1, 1):INDEX(x, b, 1))
)
)
)
)
)
);
As you can see, it’s significantly simpler than the earlier version. Here’s an example showing a rolling sum:
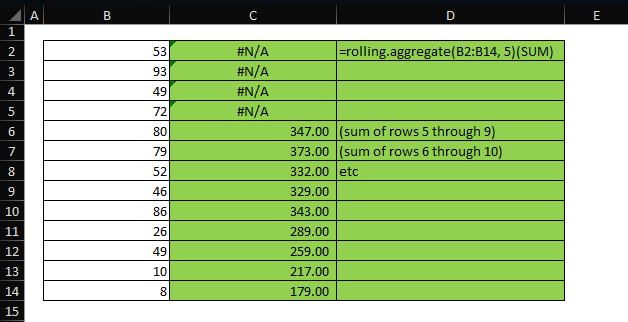
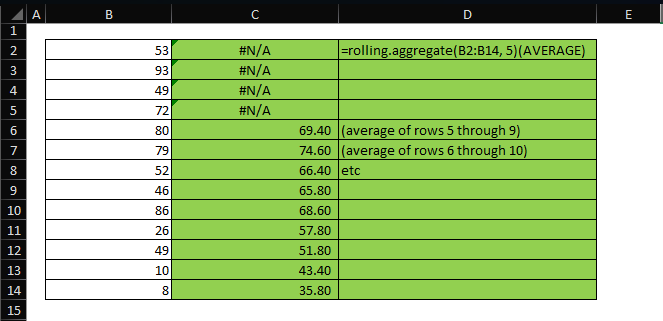
For a rolling average, we just pass a different aggregation function:
rolling.aggregate takes three parameters:
-
- x – the single-column array of numbers over which we want to calculate rolling aggregates
- window – an integer representing the size of the window, i.e. the number of most-recent rows ending in the current row, that defines the window for the aggregate that will be displayed on the current row of the output array
- function – a function with no more than one required argument that produces a scalar. For example, SUM, AVERAGE, MIN, MAX, STDEV.S, etc or a custom function such as:
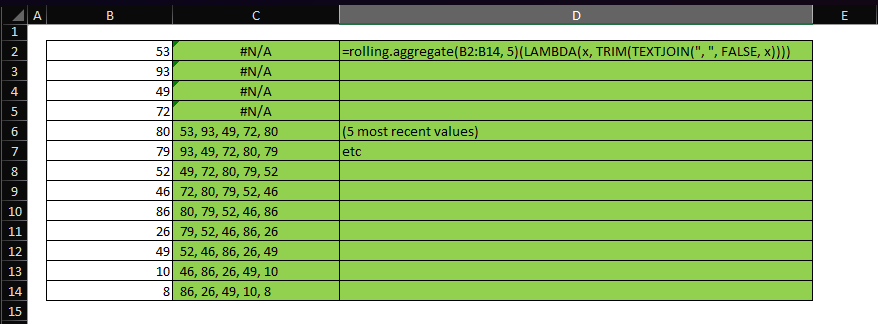
=LAMBDA(x, TRIM(TEXTJOIN(", ", FALSE, x)))
This latter function concatenates the most recent 5 values:
rolling.aggregate – how it works
For reference:
aggregate =LAMBDA(x,window,
LAMBDA(function,
LET(
_i,SEQUENCE(ROWS(x)),
MAP(_i,
LAMBDA(b,
IF(
b < window,
NA(),
function(INDEX(x, b - window + 1, 1):INDEX(x, b, 1))
)
)
)
)
)
);
The first thing to note is that this is a curried function. If you’re not sure what that means, you may want to watch this video:
If you don’t want to watch the video, a quick primer is that when we curry a function, we separate one or more parameters of a function into separate functions.
When working with Excel LAMBDA functions, we can tell that a function has been curried when the first word after a list of parameters is LAMBDA. This means that the return value of that function is a LAMBDA function.
In this example, we can think of the “outer function” as:
aggregate =LAMBDA(x,window,
LAMBDA()
);
And the “inner function” as:
LAMBDA(function,
LET(
_i,SEQUENCE(ROWS(x)),
MAP(_i,
LAMBDA(b,
IF(
b < window,
NA(),
function(INDEX(x, b - window + 1, 1):INDEX(x, b, 1))
)
)
)
)
)
So, we pass two parameters to the outer function: x – a vector (1-dimensional array), and window – an integer describing the number of rows over which the function should be applied. The return value of the outer function is the inner function, initialized with the values of x and window.
Considering the examples in the images above, x is B2:B14 and window is 5. The return value from passing those arguments to the outer function is:
LAMBDA(function,
LET(
_i,SEQUENCE(ROWS(B2:B14)),
MAP(_i,
LAMBDA(b,
IF(
b < 5,
NA(),
function(INDEX(B2:B14, b - 5 + 1, 1):INDEX(B2:B14, b, 1))
)
)
)
)
)
Note that occurrences of x are replaced with the range address B2:B14, and occurrences of window are replaced with 5. This is now a function of one parameter – function – which accepts the aggregate functions described above.
We call this function by passing the aggregate function we want to apply to the vector in parentheses after the function.
To be more specific, this is equivalent to the inner function LAMBDA above:
=rolling.aggregate(B2:B14,5)
We can think of this as preparing a function to accept whatever aggregate function we want to use at any given moment. For example:
=rolling.aggregate(B2:B14,5)(SUM)
=rolling.aggregate(B2:B14,5)(AVERAGE)
=rolling.aggregate(B2:B14,5)(MAX)
=rolling.aggregate(B2:B14,5)(LAMBDA(x, TRIM(TEXTJOIN(", ", FALSE, x))))
etc
You may be wondering “Why would we need to curry this function when we can just as easily have a single function call with three parameters?” We could do this instead:
=rolling.aggregate(B2:B14,5,SUM)
The benefit of currying the function parameter into the inner function is that we can prepare the inner function once, and use it multiple times:
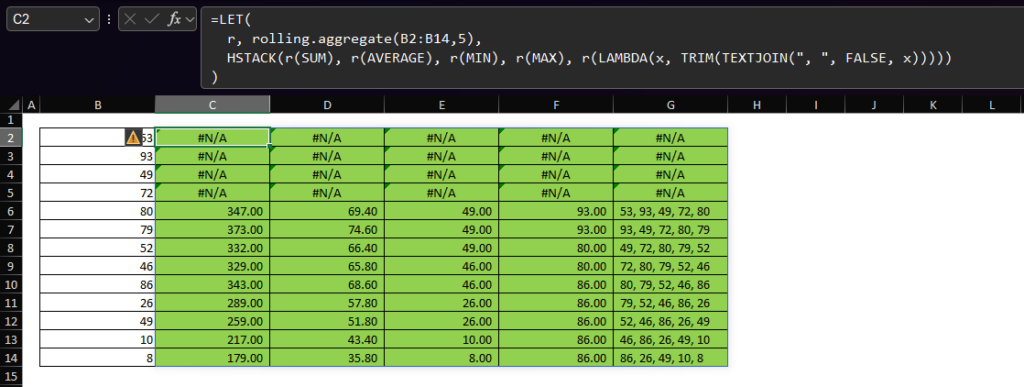
=LET(
r, rolling.aggregate(B2:B14,5),
HSTACK(r(SUM), r(AVERAGE), r(MIN), r(MAX), r(LAMBDA(x, TRIM(TEXTJOIN(", ", FALSE, x)))))
)
Which starts to make building multiple statistics over a pre-defined window size somewhat easy:
Let’s take a quick look at how the inner function works. As a reminder:
LAMBDA(function,
LET(
_i,SEQUENCE(ROWS(x)),
MAP(_i,
LAMBDA(b,
IF(
b < window,
NA(),
function(INDEX(x, b - window + 1, 1):INDEX(x, b, 1))
)
)
)
)
)
The body of the function uses LET:
- _i – this is a sequence from 1 to the count of rows in x. In the examples used above, x is B2:B14, so ROWS(x) is 13 and SEQUENCE(ROWS(x)) is {1;2;3;4;5;6;7;8;9;10;11;12;13}
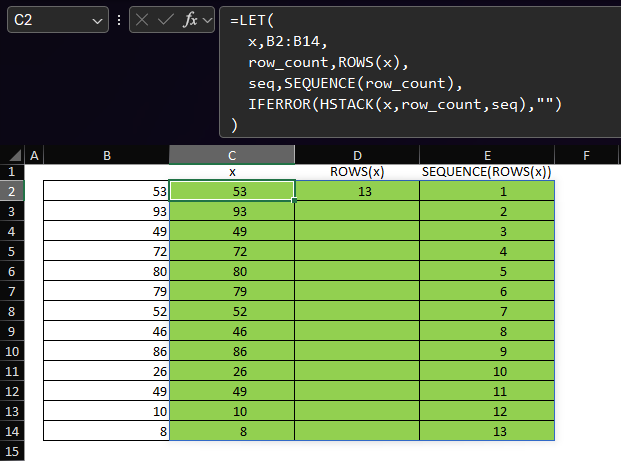
The return value of the LET call is a call to MAP. We are passing the array _i – the sequence {1;2;3;4;5;6;7;8;9;10;11;12;13} to the array1 parameter of MAP. Then, we are passing the following function to the lambda parameter of MAP:
LAMBDA(b, IF( b < window, NA(), function(INDEX(x, b - window + 1, 1):INDEX(x, b, 1)) ) )
This is just a function of one parameter – b – which represents one element from the sequence _i. The MAP function applies the expression beginning IF( b < window… to each value of b in _i.
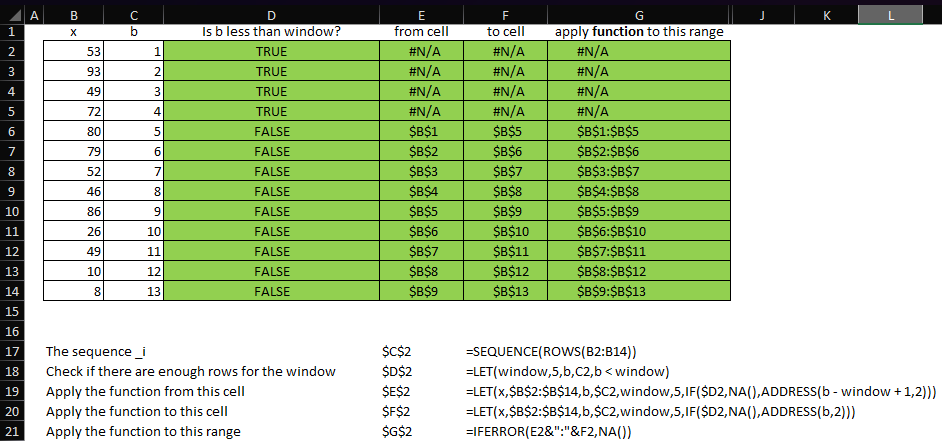
The expression INDEX(x, b – window + 1, 1):INDEX(x, b, 1) builds a reference to the row of x that is window – 1 rows prior to the current value of b to the bth row in x. This is illustrated below using the ADDRESS function. Note that the row argument passed to ADDRESS is the same as the row argument passed to INDEX.
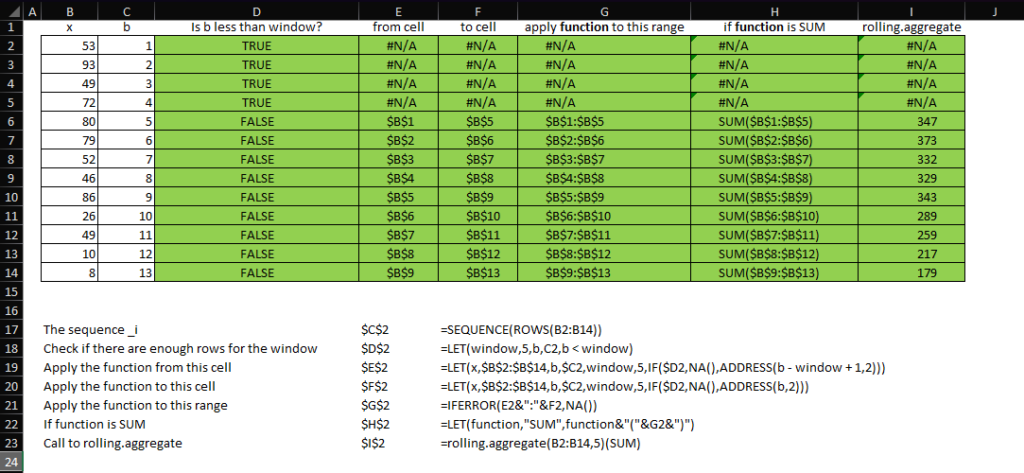
Then, the expression function(INDEX(x, b – window + 1, 1):INDEX(x, b, 1)) ) simply applies to the reference created with INDEX whatever function happens to be. For example, if function is SUM, then:
In summary
This post aimed to describe a simple but flexible way to create rolling aggregates using a custom curried lambda function.
Being able to pass native Excel functions (such as SUM, AVERAGE or MAX) as arguments to other functions allows us to create generic lambda functions whose result is controlled by a parameter.
Let me know in the comments if you have any questions about the post.
Leave a Reply