Introduction
In this post we’ll look at a way to create a LAMBDA function to calculate all pairs from two lists in Excel.
F# has a collection of functions for working with lists. Without getting into the details of F# itself, a list is a collection of items. It’s quite similar to a list in Power Query’s M language. In fact, M is so similar because it is partly based on F#.
One of the functions which can be used for manipulating and working with lists in F# is called List.allPairs. This function accepts two lists. In Excel terms, let’s equate a list with a single-column array. Or a vector, if you prefer. List.allPairs returns the result of pairing each item in the first of these two lists with each item in the second. If you’re a SQL developer, you can think of this as a cross-join.
From the documentation for List.allPairs:
let people = [ "Kirk"; "Spock"; "McCoy" ]
let numbers = [ 1; 2 ]
people |> List.allPairs numbers
Evaluates to:
[ (1, "Kirk"); (1, "Spock"); (1, "McCoy"); (2, "Kirk"); (2, "Spock"); (2, "McCoy") ]
In this post, we’ll look at one way to implement this as an Excel LAMBDA function. This LAMBDA function will let us calculate all pairs from two lists in Excel.
LIST.ALLPAIRS
Here’s the definition of the function
LIST.ALLPAIRS = LAMBDA(list1, list2,
LET(
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
list1length, ROWS(list1Col),
list2length, ROWS(list2Col),
resultRows, SEQUENCE(list1length * list2length, 1),
rowIndex1, CEILING(resultRows / list2length, 1),
rowIndex2, MOD(resultRows - 1, list2length) + 1,
HSTACK(INDEX(list1Col, rowIndex1), INDEX(list2Col, rowIndex2))
)
);
If you prefer you can import it to your own workbook from this gist.
LIST.ALLPAIRS accepts two required arguments:
- list1 – a single-column array or reference to a range
- list2 – a single-column array or reference to a range
As we’ll see in a moment, if these arguments are not single-column arrays, they will be coerced to such using TOCOL.
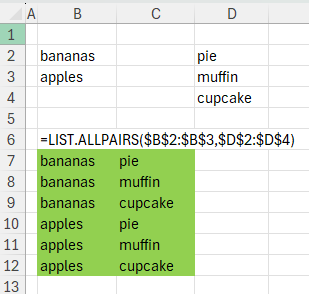
Here’s an example showing what this function does:
EXPLANATION
Let’s take a look at how this function works.
LIST.ALLPAIRS = LAMBDA(list1, list2,
LET(
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
list1length, ROWS(list1Col),
list2length, ROWS(list2Col),
...
In these first four variables, we:
- Convert both arguments to vectors using TOCOL, creating list1Col and list2Col
- Calculate the length of both vectors, creating list1Length and list2Length
Next:
...
resultRows, SEQUENCE(list1length * list2length, 1),
rowIndex1, CEILING(resultRows / list2length, 1),
rowIndex2, MOD(resultRows - 1, list2length) + 1,
...
If we are to pair every item in list1 with every item in list2, we will end up with an array with list1Length * list2Length rows, so we first create a sequence from 1 to list1Length * list2Length rows.
rowIndex1 creates an array that will be used to extract rows from list1Col. Similarly, rowIndex2 will be used to extract rows from list2Col. To understand this better, Let’s look at an example. In this revised version of the function, I’ve named the output ‘result’ and added a ‘test’ step that adds the row indices for each list alongside the output.
LIST.ALLPAIRS = LAMBDA(list1, list2,
LET(
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
list1length, ROWS(list1Col),
list2length, ROWS(list2Col),
resultRows, SEQUENCE(list1length * list2length, 1),
rowIndex1, CEILING(resultRows / list2length, 1),
rowIndex2, MOD(resultRows - 1, list2length) + 1,
result, HSTACK(INDEX(list1Col, rowIndex1), INDEX(list2Col, rowIndex2)),
test, VSTACK(
{"resultRows",
"resultRows/list2length",
"rowIndex1",
"MOD(resultRows-1, list2length)",
"rowIndex2",
"list1 value",
"list2 value"},
HSTACK(
resultRows,
resultRows/list2length,
rowIndex1,
MOD(resultRows-1, list2length),
rowIndex2,
result)
),
test
)
);
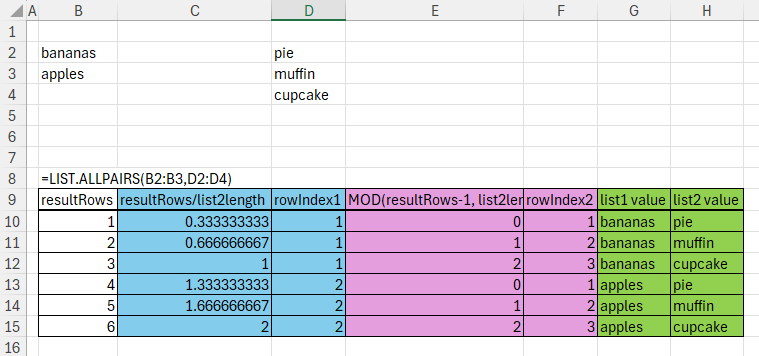
resultRows is shown in the left-most column. This is the sequence that defines how many output rows we should have.
In the second column you can see the first argument passed to CEILING. This is dividing each number in resultRows by list2length, which in this example is 3. This produces a vector where some rows are non-integers. The CEILING function raises each of these decimals to the next integer. The result of that is in the ‘rowIndex1’ column.
In the pink columns, we see the calculation for rowIndex2. The first pink column is the remainder if we were to divide the first argument of MOD (resultRows-1) by its second argument (list2length). The second pink column adds one to this remainder, to get the rowIndex2.
rowIndex1 is the index of the row from list1. rowIndex2 is the index of the row from list2. It’s not too hard to see that if we pass these arrays into the INDEX function, we’ll retrieve data from the original lists. That’s exactly what happens in the final step (i.e. the LET output) of LIST.ALLPAIRS:
LIST.ALLPAIRS = LAMBDA(list1, list2,
LET(
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
list1length, ROWS(list1Col),
list2length, ROWS(list2Col),
resultRows, SEQUENCE(list1length * list2length, 1),
rowIndex1, CEILING(resultRows / list2length, 1),
rowIndex2, MOD(resultRows - 1, list2length) + 1,
HSTACK(INDEX(list1Col, rowIndex1), INDEX(list2Col, rowIndex2))
)
);
The index variables are used to retrieve data from their respective lists and the two results are horizontally stacked together using HSTACK.
SUMMARY
In this post we looked at one way to calculate all pairs from two lists in Excel. This is a relatively straightforward approach that calculates arrays of duplicative row indices of the two lists and then stacks them together. Perhaps the most obscure part are the calculations for the two arrays, but I hope the example shown made it easier to understand.
Leave a Reply