The Excel team introduced support for regular expressions in May 2024 with three new functions
- REGEXREPLACE, which ‘allows you to replace text from a string with another string, based on a supplied regular expression (“regex”)’.
- REGEXEXTRACT, which ‘allows you to extract text from a string based on a supplied regular expression. You can extract the first match, all matches or capturing groups from the first match’.
- REGEXTEST, which ‘allows you to check whether any part of supplied text matches a regular expression (“regex”). It will return TRUE if there is a match and FALSE if there is not’.
The functions were announced in this post on the Microsoft 365 Insiders blog.
As well as these new functions, we learned that we will be able to use regular expressions with XLOOKUP and XMATCH in the near future.
Regex coming soon to XLOOKUP and XMATCH
We will also be introducing a way to use regex within XLOOKUP and XMATCH, via a new option for their ‘match mode’ arguments. The regex pattern will be supplied as the ‘lookup value’.
This will be available for you to try in Beta soon, at which point we’ll update this blog post with more details.
While we wait for that, we can mimic that functionality with lambda functions!
XMATCH.NEW
XMATCH.NEW = LAMBDA(lookup_value,lookup_array,[match_mode],[search_mode],
IF(
match_mode=3, // use regex
FILTER(SEQUENCE(ROWS(TOCOL(lookup_array))),REGEXTEST(lookup_array,lookup_value)),
XMATCH(lookup_value, lookup_array, match_mode, search_mode)
)
);
XMATCH.NEW works very similarly to XMATCH. In fact, unless we pass match_mode=3, it works identically to XMATCH.
If we pass match_mode=3, XMATCH.NEW interprets the lookup_value as a regex pattern. The pattern is tested against the lookup_array using REGEXTEST. This returns an array of TRUE/FALSE values. This array, or mask if you prefer, is passed as the include argument in the FILTER function, where the array being filtered is the positional indices of the lookup_array – SEQUENCE(ROWS(TOCOL(lookup_array))).
As a simple example, let’s use this pattern ^(?![^@\s]+@[^@\s]+.[^@\s]{2,}\s*$).+$ to find the positional indices of the invalid email addresses in this made-up dataset.
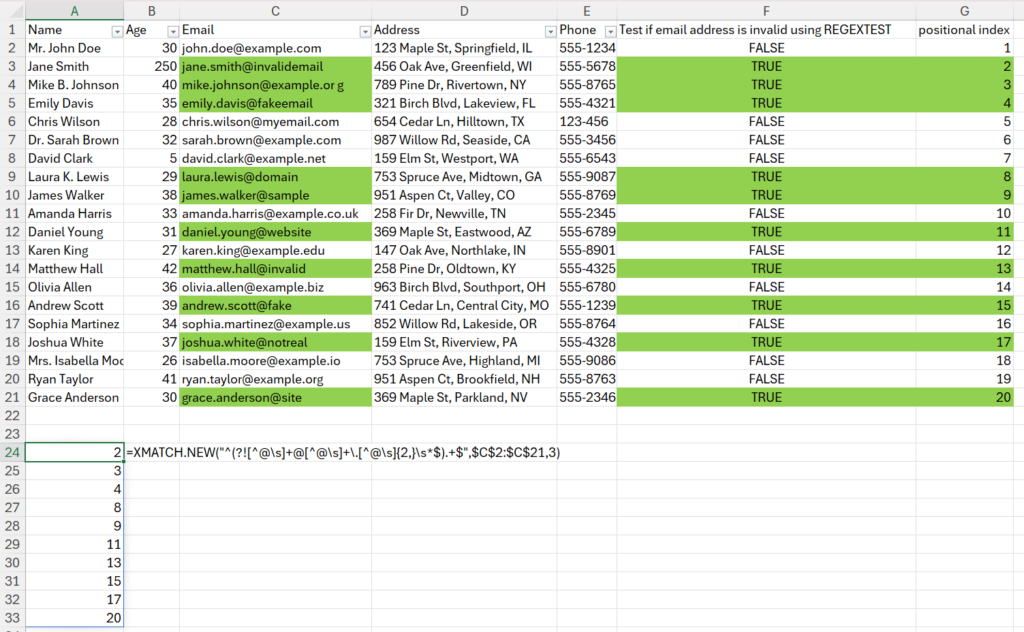
The pattern is passed as the lookup_value, the array is the range of email addresses in column C, and the match_mode is set to 3. So, the function returns the indices (shown in column G) of those rows where REGEXTEST returns TRUE (shown in column F). Whereas XMATCH only returns the first index of a valid match, XMATCH.NEW with match_mode 3 will return all matching indices.
XLOOKUP.NEW
XLOOKUP.NEW = LAMBDA(lookup_value,lookup_array,return_array,
[if_not_found],[match_mode],[search_mode],
IF(
match_mode=3, // use regex
IFERROR(
FILTER(return_array,REGEXTEST(lookup_array,lookup_value)),
IF(ISOMITTED(if_not_found),#N/A,if_not_found)
),
XLOOKUP(lookup_value,lookup_array,return_array,if_not_found,match_mode,search_mode)
)
);
XLOOKUP.NEW will behave identically to XLOOKUP unless we pass match_mode=3, in which case the pattern in lookup_value will be used in REGEXTEST to build an array of TRUE/FALSE values which are passed as the include parameter in FILTER. This time, the array being filtered will be return_array, returning the matching rows. If this filter operation returns an error, the function returns to the spreadsheet the argument supplied to the if_not_found parameter, or #N/A if no such argument was provided.
Let’s use the same invalid email address pattern to filter the data for rows with invalid email addresses:
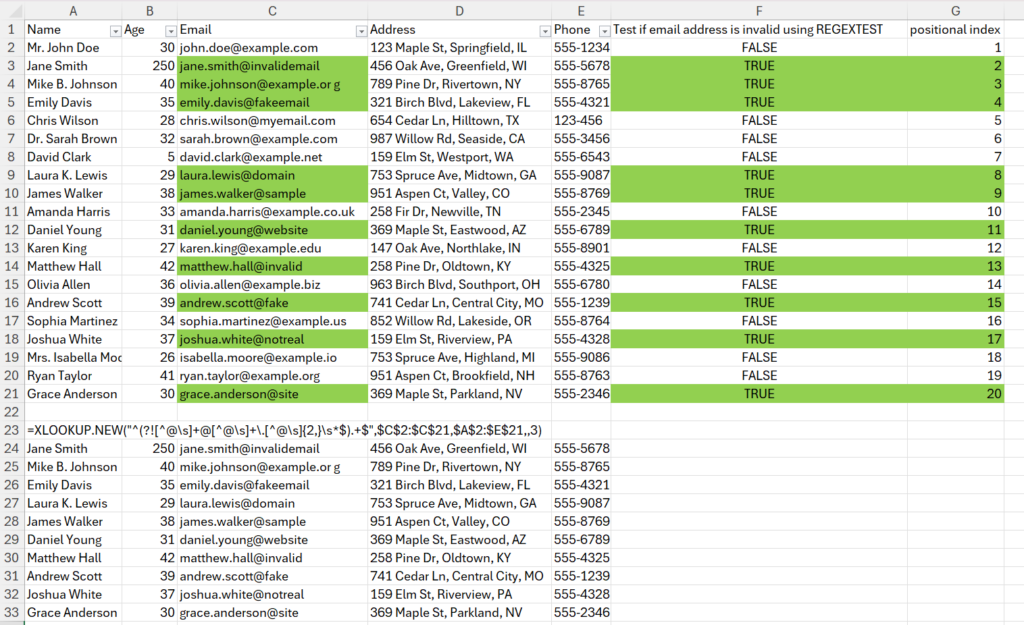
The pattern is passed as the lookup_value, the lookup_array is the range of email addresses in column C, the return_array is the range of data in columns A to E, and the match_mode is set to 3. So, the function returns those rows where REGEXTEST returns TRUE (shown in column F).
Simple!
CONCLUSION
While we wait for the official update that will allow us to use regular expressions with XLOOKUP and XMATCH, we can make some simple LAMBDA functions that will mimic this behavior, and start to practice our regular expressions now!
Click here for another post about regular expressions, and why “just get it from AI” is not going to be good enough.
Leave a Reply