This post will teach you how to write better regex with look-behinds and look-aheads. All the images in this post are from regex101.
An example problem
Take these text strings for example:
{123} {4567] (890)
{12}34{56}
[1]2(3]
{1[23]4}
{12(34)}
Suppose we want to write a regular expression that extracts all numbers of one or more digits that are enclosed by matched brackets. When I say matched brackets, I mean any of these:
{ }
( )
[ ]
We can see that the first line has the number 123 within { }, and the number 890 within ( ). The number 4567 is not counted because its opening bracket is { and its closing bracket is ].
We can start by noting that the regular expression \d will capture any digits:

This first expression has captured all the digits, but it has captured too many. Not only has it captured the digits within unmatched brackets, but it’s also captured digits that are within brackets with other characters within. For example, in the string {1[23]4}, we only want to capture 23. Furthermore, because we only put \d, we have captured each digit individually and not the full numbers – the strings of digits.
If we add the + operator at the end, we now capture strings of one or more digits:
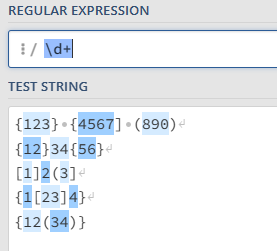
This is better, but we are still capturing digits that we don’t want.
We can improve on this by saying that we want there to be a bracket before and after the numbers. For example:
[{\[(]\d+[}\])]
Before the \d+, we have this:
[{\[(]
By enclosing a string of characters within square brackets, we are saying that we want to find one of the characters within that string. Within the outer square brackets are the following characters:
{
\[
(
These are just the opening brackets we’re looking for, noting that the opening square bracket is escaped by placing a forward-slash before it. This tells the interpreter to treat the following character as a literal, instead of a regex special character. Normally a square bracket indicates the beginning of a character set, as mentioned above.
After the digits, we have this:
[}\])]
which can be explained in a similar way. i.e. capture one of }, ] or ).
This improves the capture of the correct numbers, but now we have the brackets captured as well:
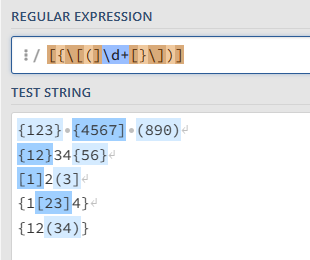
Enter positive look-behinds!
Luckily for us, we have a way to express sentences like this:
“Any string of numbers that immediately follow an opening bracket, without capturing the bracket itself”
A positive look-behind takes this form:
(?<=regex)
Where ‘regex’ is replaced by the pattern that expresses what to look for before the pattern of interest. The rest of the positive look-behind syntax is always the same. Always (?<=, then the expression you want to use, then ). There are also negative look-behinds, whose syntax is like this:
(?<!regex)
I’m not going to go into details of this, but hopefully it’s not too much of a stretch to figure out what a negative look-behind is for!
Back to our problem, we can make our regex more precise by replacing the beginning with a positive look-behind, like this:
(?<=[{\[(])\d+[}\])]
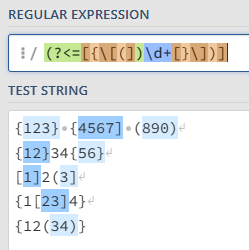
You can see now that the matched text no longer includes the opening bracket, though the expression is checking for its existence.
So how do we deal with that closing bracket?
Enter positive look-aheads!
It’s probably no surprise that there is a similar construct for expressing statements like this:
“Any string of numbers that immediately follow an opening bracket and are immediately followed by a closing bracket, without capturing the brackets themselves”
The syntax is like this for a positive look-ahead:
(?=regex)
Similarly, regex is replaced with the expression you want to check after a capture group.
So this expression deals with both opening and closing brackets:
(?<=[{\[(])\d+(?=[}\])])
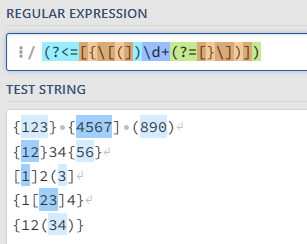
Great progress! There’s one remaining issue. We are still capturing those numbers enclosed within unmatched brackets. We don’t want to capture 4567 on the first line, and we don’t want to capture 3 on the third line.
To do this, we need to express ourselves in this way:
“A string of digits immediately after an opening brace and immediately before a closing brace OR a string of digits immediately after an opening square bracket and immediately before a closing square bracket OR a string of digits immediately after an opening parenthesis and immediately before a closing parenthesis“
Whew! That’s a mouthful. But it’s probably no surprise that we can just copy, paste and modify the expression above to get a longer expression that mirrors the requirement:
(?<=\{)\d+(?=\})|(?<=\[)\d+(?=\])|(?<=\()\d+(?=\))
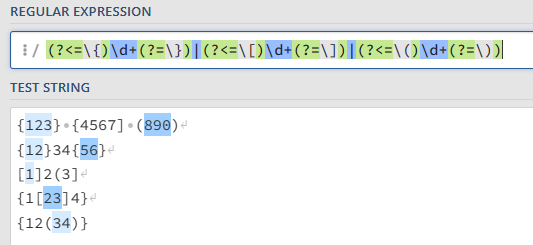
Note how we now effectively have three regular expressions separated by the pipe character |. This is used to represent OR. Before the first pipe character is the expression to capture numbers within braces { }. The middle expression is to capture numbers within square brackets [ ]. The last expression is to capture numbers within parentheses ( ).
Conclusion
With a few modifications, we saw how to get better regex results using look-behinds (positive, to be precise) and positive look-aheads.
Sometimes when using regular expressions, we might need to iteratively modify the expression to get exactly what we want.
If you’re smart, you will no doubt rely on tools like ChatGPT in the future to help you get the regex you want, but please heed this word of warning:
If you don’t express yourself incredibly precisely in your prompt, the regex the AI gives you may only appear to be giving you the right results.
With knowledge of constructs like look-behinds and look-aheads, you can specify exactly what you want in your prompt and get better results.
Good luck!
Leave a Reply