The gist for this lambda function can be found here.
A friend of mine challenged me to implement a LAMBDA to calculate the Levenshtein Distance in Excel.
As a reminder, the Levenshtein Distance represents the fewest number of insertions, replacements or deletions that are necessary to change one text string into another. For example, given the words “kitten” and “sitting”, we need these operations to change the former to the latter:
- Replace the k with an s
- Replace the e with an i
- Insert a g at the end
We can think of this as a measurement of similarity between two strings. The smaller the number of operations, the more similar the strings are.
I used this page on the Wagner-Fischer algorithm to guide my work.
I call it LEV:
=LAMBDA(a,b,[ii],[jj],[arr],
LET(
i,IF(ISOMITTED(ii),1,ii),
j,IF(ISOMITTED(jj),1,jj),
a_i,MID(a,i,1),
b_j,MID(b,j,1),
init_array,MAKEARRAY(
LEN(a)+1,
LEN(b)+1,
LAMBDA(r,c,IFS(r=1,c-1,c=1,r-1,TRUE,0))
),
cost,N(NOT(a_i=b_j)),
this_arr,IF(ISOMITTED(arr),init_array,arr),
option_a,INDEX(this_arr,i+1-1,j+1)+1,
option_b,INDEX(this_arr,i+1,j+1-1)+1,
option_c,INDEX(this_arr,i+1-1,j+1-1)+cost,
new_val,MIN(option_a,option_b,option_c),
overlay,MAKEARRAY(
LEN(a)+1,
LEN(b)+1,
LAMBDA(r,c,IF(AND(r=i+1,c=j+1),new_val,0))
),
new_arr,this_arr+overlay,
new_i,IF(i=LEN(a),IF(j=LEN(b),i+1,1),i+1),
new_j,IF(i<>LEN(a),j,IF(j=LEN(b),j+1,j+1)),
is_end,AND(new_i>LEN(a),new_j>LEN(b)),
IF(is_end,new_val,LEV(a,b,new_i,new_j,new_arr))
)
)
LEV has two required parameters:
- a – a string you want to compare with b
- b – a string you want to compare with a
There are three optional parameters which are used by the recursion, but generally you would never need to use them:
- [ii] – an integer representing the [ii]th character position of string a
- [jj] – an integer representing the [jj]th character position of string b
- [arr] – an interim array created by LEV
This is what LEV does:

You can grab it and use it without reading the rest of the post, but if you want to understand how it works, then read on.
How it’s done
Let’s break it down.
=LAMBDA(a,b,[ii],[jj],[arr],
LET(
i,IF(ISOMITTED(ii),1,ii),
j,IF(ISOMITTED(jj),1,jj),
a_i,MID(a,i,1),
b_j,MID(b,j,1),
init_array,MAKEARRAY(
LEN(a)+1,
LEN(b)+1,
LAMBDA(r,c,IFS(r=1,c-1,c=1,r-1,TRUE,0))
),
If you read the wiki page about the Wagner-Fischer algorithm, this is all going to make more sense. I also recommend this medium article.
We start by using LET to create some variables:
| name | definition |
|---|---|
|
i is an integer representing the position of a character in string a. When we call LEV from the spreadsheet, ii is omitted, so i is initialized as 1. Later in the function, new_i is created and new_i is passed to ii in the recursive call to LEV. When LEV is called by LEV, i is set to ii by this variable definition. i is used to iterate through each letter in the string a |
|
|
j is defined similarly to i, but this time it is used for iterating through the letters in the string b |
|
| This returns the character of string a at position i | |
| Returns the character of string b at position j | |
|
init_array is where the algorithm starts. We use MAKEARRAY to create an array with LEN(a)+1 rows and LEN(b)+1 columns. We populate that array by placing the integers 0..LEN(a) in the first column and 0..LEN(b) in the first row and 0 everywhere else. |
|
Let’s take the kitten/sitting example.
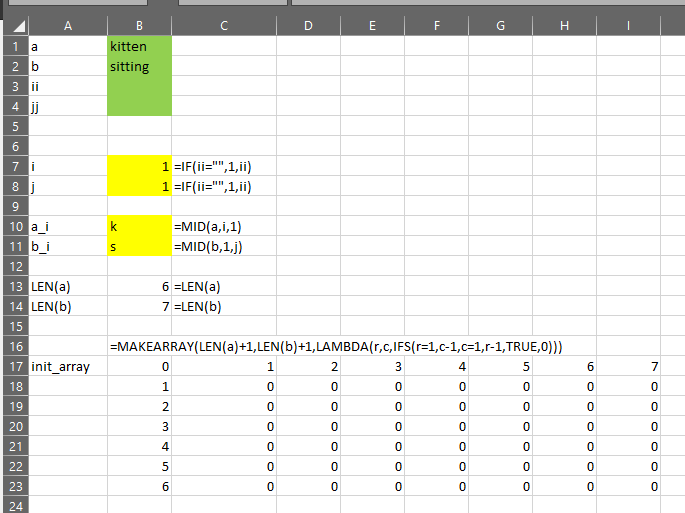
In the image above, I’ve named the cells in B1:B4,B7:B8 to correspond to the variables in the formulas.
You can see that because ii and jj are blank, i and j both become 1. ii=”” is a substitute expression for ISOMITTED(ii).
a_i returns “k”, the [i]th letter from kitten and b_i returns “s”, the [j]th letter from sitting. In this example, because i=1, we are getting the first letter from kitten. Because j=1 we are getting the 1st letter from sitting.
The length of a and b are shown in rows 13 and 14.
The initial array is shown in B17:I23. Because this is a dynamic array, the formula is only in B17.
The algorithm will begin in position [2,2] of init_array. It will fill in each of the 0 cells until it reaches the bottom-right corner. The value that is placed in the bottom-right corner is the Levenshtein Distance
cost,N(NOT(a_i=b_j)),
this_arr,IF(ISOMITTED(arr),init_array,arr),
option_a,INDEX(this_arr,i+1-1,j+1)+1,
option_b,INDEX(this_arr,i+1,j+1-1)+1,
option_c,INDEX(this_arr,i+1-1,j+1-1)+cost,
new_val,MIN(option_a,option_b,option_c),
overlay,MAKEARRAY(
LEN(a)+1,
LEN(b)+1,
LAMBDA(r,c,IF(AND(r=i+1,c=j+1),new_val,0))
),
new_arr,this_arr+overlay,
We continue to define more calculations in LET:
| name | definition |
|---|---|
|
The cost compares the character a_i with the character b_j. If they are the same, then that comparison returns TRUE. NOT(TRUE)=FALSE and N(FALSE)=0 Similarly, if those characters are not the same, then that comparison returns FALSE. NOT(FALSE)=TRUE and N(TRUE)=1 In the example above: N(NOT(“k” = “s”)) = 1 |
|
|
This represents the state of the array at the beginning of this iteration. If this is the first iteration (i.e. LEV was called by something other than itself), then this is init_array, otherwise it’s whatever array was provided to the parameter [arr]. You will see below that when LEV calls LEV, it passes a modified array into the [arr] parameter. |
|
At this point, if you’re not familiar with this algorithm, I encourage you to read the medium article I linked above, which I will link again here.
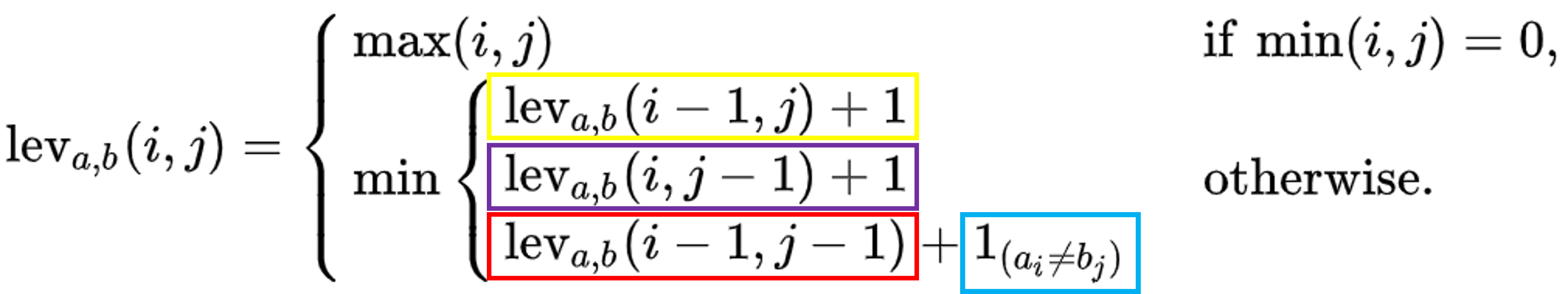
Each cell in our array is calculated using the expression above.
If you’re not familiar with this kind of expression, don’t worry. The brace { is how options are presented. In this case, we have two options:
- Where min(i,j) = 0, for when we are comparing character position 0 in either string (i or j) with any other character position in the other string. In this option, we put max(i,j) in the array. This is what creates the row headers and column headers of init_array
- “otherwise”, which represents every cell in the array that is not on the first row and is not in the first column. So this is the section of the init_array which is currently filled with zeroes. So we know that each cell currently holding a zero (except [1,1]), needs to be filled with the minimum of those three options
| name | definition |
|---|---|
|
This is the expression in the yellow box. This option takes the value from the array that is one column to the left of the current position. If the current position in the array is this_arr[2,2], then option_a is this_arr[2,1], which happens to be the number 1. Adding 1 to this value gives 2, so option_a=2 when we are starting from this_arr[2,2] |
|
|
This is the expression in the purple box. This option takes the value from the array that is one row above the current position. If the current position in the array is this_arr[2,2], then option_b is this_arr[1,2], which happens to be the number 1. Adding 1 to this value gives 2, so option_b=2 when we are starting from this_arr[2,2] |
|
|
This is the expression in the red box plus the expression in the blue box. The expression in the blue box is the cost (defined above). This option takes the value from the array that is one row above and one column to the left of the the current position. If the current position in the array is this_arr[2,2], then option_c uses this_arr[1,1], which happens to be the number 0. Adding 1 (the cost) to this value gives 1, so option_c=1 when we are starting from this_arr[2,2] |
|
|
The new value that will be placed into the array is the minimum of options a, b and c |
|
|
The overlay is an array with the same dimensions as init_array. It has zero in every cell except the cell just calculated, which contains new_val |
|
|
overlay is added to this_arr. new_arr therefore is the same as this_arr with one difference: the cell being calculated during this iteration now contains new_val |
|
new_arr,this_arr+overlay,
new_i,IF(i=LEN(a),IF(j=LEN(b),i+1,1),i+1),
new_j,IF(i<>LEN(a),j,IF(j=LEN(b),j+1,j+1)),
is_end,AND(new_i>LEN(a),new_j>LEN(b)),
IF(is_end,new_val,LEV(a,b,new_i,new_j,new_arr))
)
)
Now that we have calculated the new value and the new array, we are ready to move to the next cell and calculate that. Some more calculations, remembering that the array we are populating has the character positions i of a on the rows and the character positions j of b on the columns:
| name | definition |
|---|---|
|
new_i is the new value for i that we will pass into the ii parameter of the next call to LEV. If i is the last character position of a, then we have reached the last row of the array, so: if j is at the last position of b then we have reached the last column of the array, in which case we simply add 1 to i, otherwise we set i to 1 (i.e., return to the first character position of a – because we are going to move to the next column). Lastly, if i is not at the last position of a, then we move to the next position of a (i.e. the next row in the array) |
|
|
new_j is the new value for j that we will pass into the jj parameter of the next call to LEV. If i is not at the last character position of a (i.e. it is not on the last row), then set new_j to be equal to j (stay on the same column). Otherwise, if j is at the last character position of b, then add 1 to j, otherwise add 1 to j. This may seem redundant, but writing it this way helps my understanding as the first outcome represents “move off the array” and the second outcome represents “move to the next column” |
|
|
Here we are testing if both new_i and new_j are greater than the length of their respective strings. Because of the way new_i and new_j are defined above, if this condition is TRUE, then we have reached the bottom-right corner of the array and we need to stop |
|
The final expression of LET is IF(is_end,new_val,LEV(a,b,new_i,new_j,new_arr)).
If we are at the end, then return new_val. Otherwise, call LEV with a, b, new_i, new_j and new_arr.
Put simply: Move to the next zero-cell in the now-updated array and perform the same calculations involving options a, b and c and the cost as defined above.
The algorithm continues in this way until it reaches the bottom-right corner, at which point it returns the result to the worksheet.
Here is a mocked up example of the state of all those variables during the first iteration:
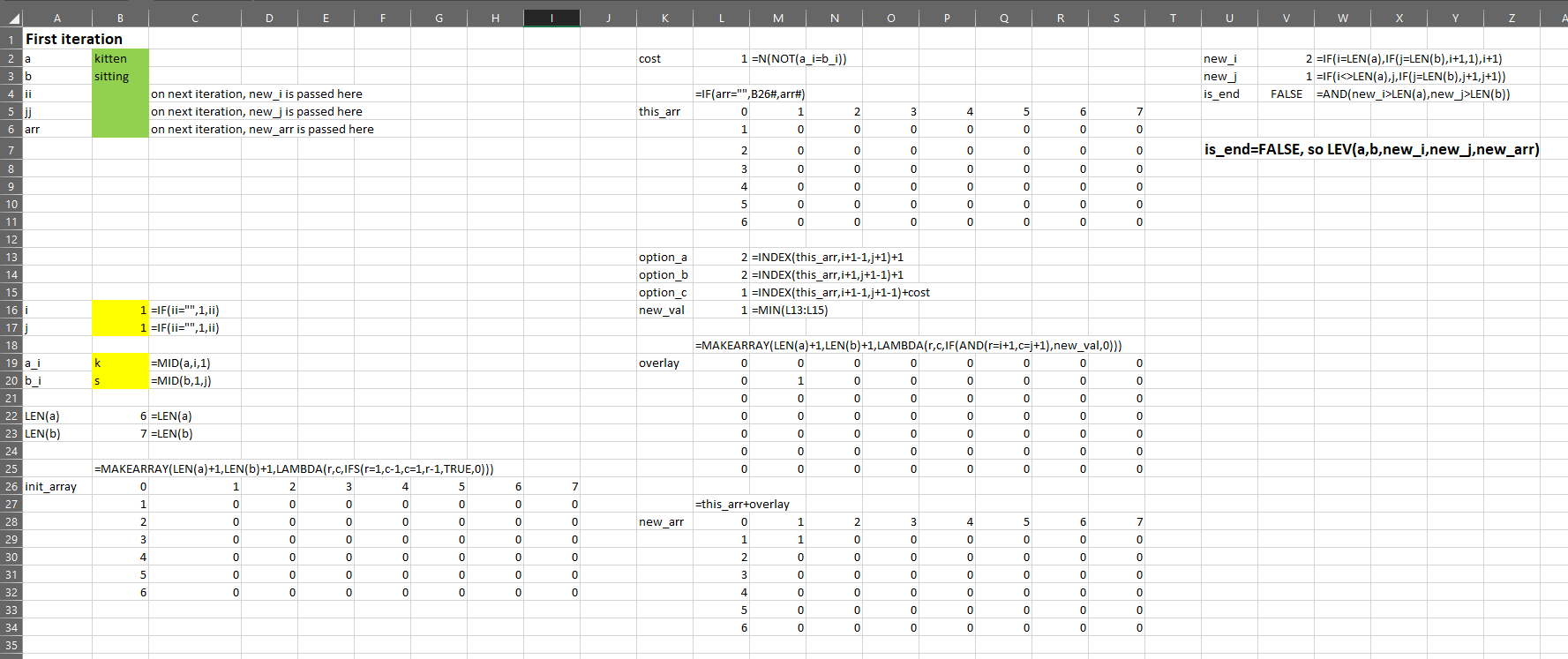
A word of caution: you’ve seen that this involves LEN(a)*LEN(b) iterations to get to a result, so the longer the strings, the more iterations needed.
To sum up
This was a fun experiment!
Now we know how to calculate the Levenshtein Distance in Excel using LAMBDA. There are all kinds of uses for this – name matching, address matching, product matching and so on.
I hope that this post has inspired you to think of ideas to use recursive lambda functions to solve tasks you are working on.
If you’ve got something you want to solve and aren’t sure where to get started, you can ask me directly in the comments here.
Leave a Reply